Robots.txt: ¿Qué es, para qué sirve y cómo crearlo?
¿Sabes qué es el archivo robots.txt y para qué sirve? ¿Te gustaría conocer como puedes bloquear urls de tu web para que los bots de Google no las rastreen más?
En este artículo, vamos a hablar sobre todo esto y mucho más para que sepas cómo usar el robots.txt para seo de forma correcta.
Que es el robots.txt y para qué sirve
El archivo Robots.txt, es un archivo de texto que nos va a ser de vital importancia si nos dedicamos al seo de forma profesional.
La lógica de que exista este documento y que sea tan utilizado por los profesionales del posicionamiento orgánico, es la siguiente:
Cuando subimos una web online, la forma que tiene Google de indexar y posicionar nuestro contenido en los buscadores, es mediante los propios robots o arañas de Google.
De este modo, estos bots entran en nuestra web, y empiezan a rastrear todo el site, saltando de url a url mediante anchors text y enlazado interno (de aquí la importancia de trabajar una buena estrategia de interlinking).
Pero eso no es todo: Obviamente, estas arañas no tienen todo el tiempo del mundo para rastrear nuestro site, y es por eso que tienen un crawl Budget para cada vez que entran a nuestra web. Nota: * Cuando hablamos de crawl Budget o presupuesto de rastreo, hacemos referencia al tiempo máximo que van a estar los robots de Google rastreando nuestra web.
Dicho esto: como estas arañas tienen el tiempo limitado, será de vital importancia guiarlas para que cuando entren en nuestro site, vayan a rastrear las urls de mayor importancia vs las menos importantes (y ya no decimos las que no queremos que indexe, pues de ser así, estarán perdiendo el tiempo).
Así pues, el robots.txt es una guía o mapa que le va a servir a Google para saber las urls que debe dar prioridad en el rastreo, y en consecuencia, aquellas que no debe perder el tiempo rastreando.
Así pues, en este documento guía, especificaremos las urls que queremos que rastree, y bloquearemos aquellas otras que no queremos que siga.
IMPORTANTE: No es obligatorio configurar el robots.txt, pues Google va a entrar de todos modos a rastrear nuestra web, y lo va a seguir haciendo de forma periódica tal y como lo hace con todos los sites. Lo que sí que, si nos dedicamos al SEO de forma profesional o tenemos nociones, es recomendable configurar y subir este archivo guía a nuestra web, ya que le podremos optimizar el rastreo de los robots o arañas. Esto, obviamente, va a ser otro de los factores importantes de posicionamiento seo.
Disclamer:* Si no configuramos el archivo robots.txt, Google va a rastearlo TODO (cuando decimos “TODO”, hacemos referencia a todas las urls internas que pueda acceder mediante links).
Este, es un documento que deberemos subimos a la raíz de nuestro sitio web, y como ya hemos comentado, que utilizamos para impedir que los robots rastreen contenido que no deseamos que Google indexe ni muestre en sus resultados.
Pongamos un ejemplo: imaginemos que tenemos e-commerce, el cual tiene una barra de búsqueda para que el usuario pueda encontrar productos.

Para cada búsqueda que éste haga, se va a generar una url que puede ser más o menos así: www.example.com/catalogsearch/result?q=hola
Evidentemente, este tipo de urls no las vamos a querer indexar. Así que mejor ahorrar el tiempo de rastreo a los robots para que centren el foco en crawlear las urls más importantes.
Normativas del archivo Robots.txt
- El archivo debe llamarse robots.txt: Con esto queremos decir que, a diferencia del sitemap.xml (que puede llamarse de diferentes formas), el archivo de robots solo puede llamarse de una sola forma para que Google lo identifique correctamente: “Robots.txt” (y obviamente, debe estar en formato texto).
- Solo puede haber un archivo robots.txt por sitio web: Esto es súper importante. Y es que, si tenemos que actualizar dicho archivo, la forma de hacerlo correctamente es la de sobrescribir la información en el mismo documento. NUNCA debe crearse otro documento aparte.
- El archivo robots.txt debe incluirse en la raíz del host del sitio web al que se aplica: Tal y como hemos puntualizado en la introducción, este archivo deberá incluirse en la raíz de la web. Si utilizas gestores de contenidos como Wordpress, Prestashop u otros, por lo general encontrarás extensiones que te van a permitir integrar este archivo de texto de forma fácil y cómoda.
- El sistema de las reglas distingue entre mayúsculas y minúsculas: Esto será importante a la hora de configurar las órdenes. En caso contrario, puede que la orden no se ejecute tal y como queremos.
Cómo verificar el Robots.txt
Para comprobar que el archivo de robots lo hemos configurado correctamente, deberemos acceder al comprobador de robots.txt, donde podremos verificar que se están cumpliendo las reglas que hemos especificado.
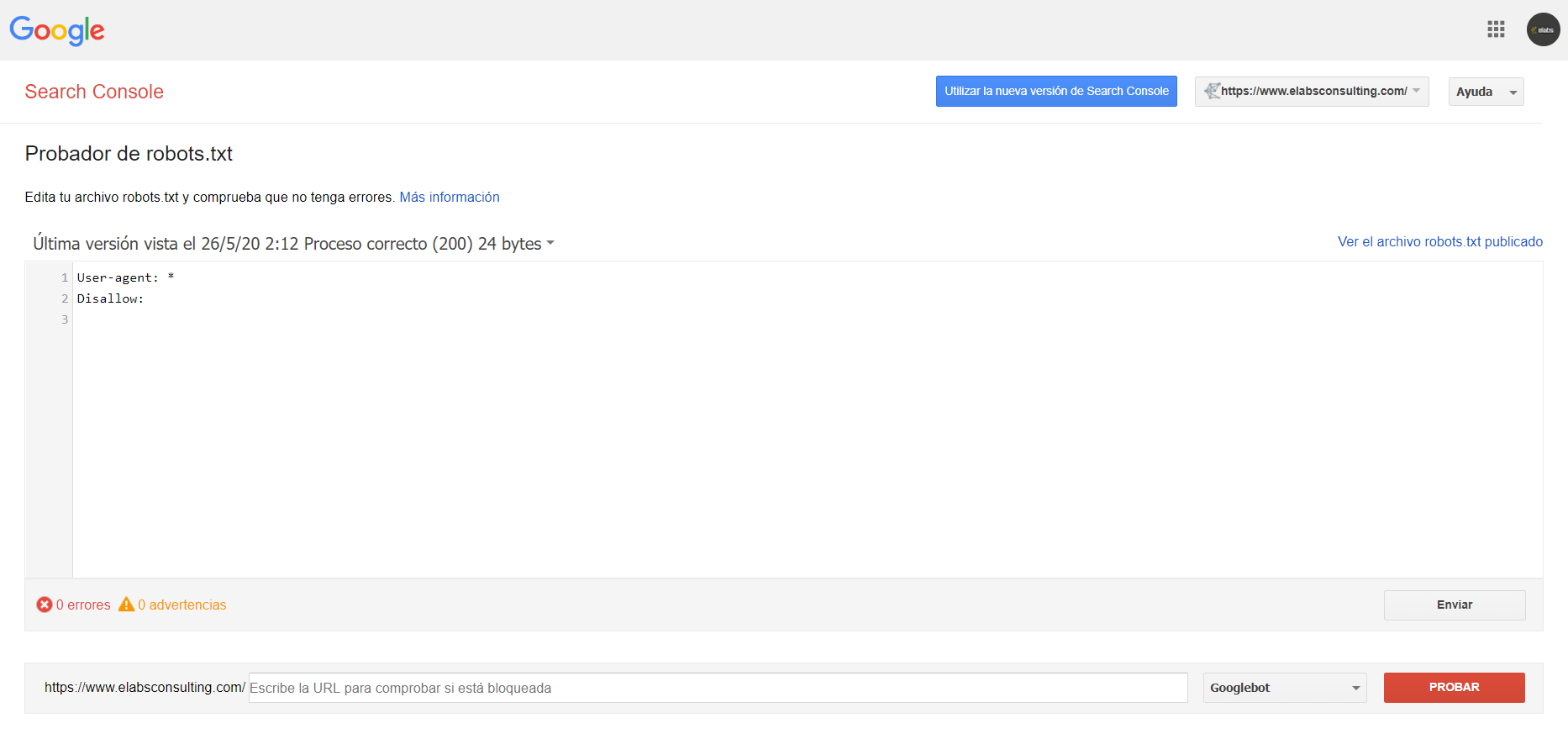
Una vez hemos accedido al comprobador de robots.txt, nos vamos a encontrar una pantalla como esta.
Aquí vamos a ver lo mismo que puede ver un usuario normal y corriente escribiendo en la barra de búsqueda de Google tu dominio + “/robots.txt”.
Ejemplo: www.elabsconsulting.com/robots.txt
En esta imagen, podemos ver como le estamos diciendo a los robots que accedan a rastrear todo el contenido de la web, sin ningún tipo de restricción.
Comandos para los robots
User-agent: o agente de usuario, son los robots o arañas de los motores de búsqueda, puedes ver a la mayoría de ellos en esta base de datos de robots web.
Google: Googlebot
Google Images: Googlebot-Image
Bing: Bingbot
Yahoo: Slurp
Baidu: Baiduspider
DuckDuckGo: DuckDuckBot
“Disallow:” indica al agente de usuario o user agent que no debe acceder, rastrear ni indexar una URL, subdirectorio o directorio concreto.
Aplicación práctica:
“Allow:” surge como contra al anterior. con él indicas al rastreador una URL, subdirectorio o directorio al que si debe entrar, rastrear o indexar.


Directrices avanzadas del Robots.txt
A continuación, os dejamos algunas de las directrices o comandos más avanzados que nos encontramos de forma habitual en Elabs, para que podáis incluir en vuestro archivo de Robots.txt.
User-agent: *
Disallow: /c?*
Disallow: /login-action.html
Disallow: /login.html
Disallow: /register.html
Disallow: /*|
Disallow: /*lvr=
Disallow: /*sel=
Disallow: /*prmax=
Disallow: /*prmin=
Disallow: /*lux=
Si quieres más información sobre cómo implementar el archivo de robots.txt o cómo usarlo, puedes consultar más aquí.
Cómo crear un archivo robots.txt
Vista la aplicación práctica del robots.txt y sus directrices más populares, pasamos a ver cómo crear uno:
Para hacerlo fácil, os recomendamos que lo creéis con el bloc de notas mismo, ya que lo vamos a poder guardar fácilmente en formato texto (.txt).
Paso 1: Abrimos el blog de notas.
Paso 2: Escribimos la primera directriz obligatoria:
User-agent: *
(Con esto, le estaremos diciendo a Google que queremos que accedan a rastrear nuestra web todos los bots que existan: las arañas de Google, Bing, Ahrefs, Duck Duck Go…).
Si por lo contrario queremos prohibir la entrada de algún robot (por ejemplo el de “Bing”), deberemos indicarlo:
User-agent: Bingbot
Paso 3:
A continuación, empezaremos a darle las instrucciones más específicas que queremos que los robots sigan, por ejemplo, que no tengan en cuenta todas las urls (útil para cuando tenemos un entorno de pruebas o QA), o que no tenga en cuenta ciertos tipos de urls.
Ejemplo de que queremos que no rastree NADA de nuestra web:
User-agent: *
Disallow: /
Ejemplo de que queremos que no rastree algunas urls con parámetros específicos de nuestra web:
User-agent: *
Disallow: /*?order=
Disallow: /*?tag=
Disallow: /*?id_currency=
Disallow: /*?search_query=
Disallow: /*?back=
Disallow: /*?n=
Observación*: Puede que a lo largo del análisis de un archivo de robots.txt, nos encontremos un trozo de texto precedido por “#”.
El uso del hashtag, almohadilla o # en robots.txt, es simplemente para indicar un comentario. Pero el texto que vaya seguido justo después de este símbolo, no va a influenciar en las órdenes de los rob


