¿Estás buscando un tutorial que te explique paso a paso cómo hacer una auditoría con Screaming frog?
En este artículo te vamos a explica qué es Screaming frog, y todas las consideraciones que tienes que tener en cuenta antes de usar la herramienta.
¿Preparado para conocer cómo funciona este SEO Spider?
¿Qué es Screaming Frog y para qué sirve?
Screaming frog es un SEO Spider (herramienta semi-gratuita) que nos permite analizar una web de arriba a bajo (ya sea nuestra, de un cliente, o de la competencia), para comprobar el estado de salud de las urls de un site, enlaces internos y externos, hacer un mapa de la estructura web…
A todo esto, la ventaja principal es que simula el rastreo tal y como lo hacen los mismo . Esto es muy poderoso, ya que nos va a devolver un análisis detallado tal y como lo ve Google.
Por cierto, arriba de todo de este artículo, te hemos dejado un vídeo tutorial de Screaming Frog, donde te explicamos todo lo que vas a encontrar en este artículo, pero de forma más dinámica.
¿Cómo funciona y para qué sirve Screaming Frog?
Saber cómo usar Screaming frog, es útil a todos los niveles, y más cuando lo tienes que utilizar para un proyecto SEO de forma profesional. Así pues, en este curso de Screaming Frog te vamos a contar las principales características que debes conocer, si todavía no estás familiarizado con este SEO spider.
Pero… ¿en qué situaciones nos va a ser útil Screaming Frog?
Al principio de un proyecto: Nos encontramos en la situación que nos llega una web nueva, y no sabemos en qué estado se encuentra (dejando a un lado lo que nos pueda decir el cliente, ya que para ir sobre-seguros, siempre será mejor que comprobemos el site con nuestros propios ojos). En este punto inicial, Screaming frog jugará un papel fundamental dentro de la auditoría SEO de la web, y por lo tanto nos será útil para situarnos y ver a grandes rasgos como se encuentra todo. Para ello, las funcionalidades principales en las que nos fijaremos, son las siguientes:
- Estructura web (Menú superior > Visualizaciones > Crawl Tree Graph).
- Salud de las urls (Errores 4xx, Redirecciones 3xx, Errores de servidor 500, páginas que no responden).
- Metatags: Comprobar si faltan titles o hay de repetidos, lo mismo con las metadescriptions y los encabezados…
- Canonicals: ¿Cuántas etiquetas canonicals hay de entre todas las urls? ¿Faltan canonicals?
- URLs: ¿Hay urls duplicadas?
A lo largo del proyecto SEO: A medida que vayamos avanzando en el proyecto, iremos haciendo modificaciones del site (quick wins o factores rápidos de hacer y con resultados visibles de forma inmediata/a corto plazo). A medida que vayamos haciendo estas modificaciones, deberemos ir con cuidado de que la web sigue igual y no se ha roto nada. Para ello, deberemos fijar nuestro foco de atención en los siguientes puntos:
- Errores 4xx
- Redirecciones 3xx
- Errores servidor 5xx
- No response
Final del proyecto: A decir verdad, cuando estamos optimizando una web para SEO, siempre hay cosas para hacer y mejorar. Así que mentiríamos si os dijéramos que existe un punto y final en cuanto a SEO se refiere. Así pues, tomaremos este punto para cuando llevamos a cabo una migración, cuando pasamos un proyecto de pre-producción o test a producción (es decir, hacer visibles todos los cambios al público y que empiece a indexar), o simplemente cuando hacemos acciones grandes que corran el riesgo de romper alguna parte de la web. Así pues, sea cual sea la situación en la te encuentres, los puntos que deberemos tener en cuenta son los siguientes:
- Salud de las urls (4xx, 3xx, 5xx, No response).
- Revisión de metatags (Title, meta description, H1, H2…)
- Indexación de las urls (véase en la columna de “Indexability”).
- Ahreflang
Partes de Screaming Frog
Así pues, una vez vistas las diferentes situaciones donde podemos utilizar Screaming Frog, vamos a ver cómo es la interfaz, y cuáles son las principales secciones que nos serán de más utilidad:
Sección 1: El menú.

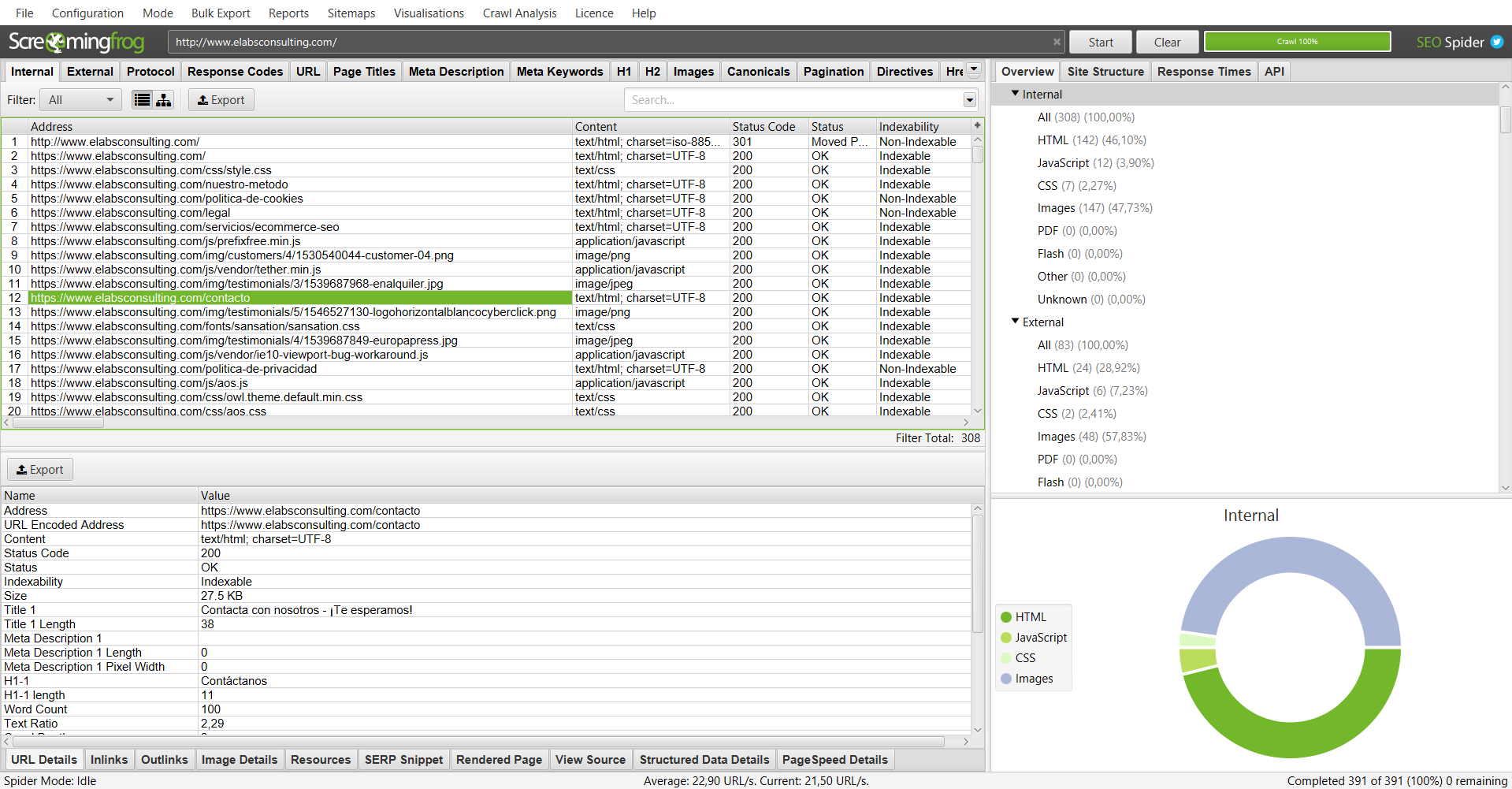
En este primer apartado, encontraremos todas las opciones avanzadas que nos proporciona la herramienta de Screaming Frog. En ella, se incluyen funcionalidades como las de limitar el rastreo mediante filtros y condiciones, rastrear el sitemap, tipos de búsqueda (buscar mediante una url principal, o analizar un listado de urls en concreto), exportar los datos, y configuraciones más avanzadas.
Sección 2: Funcionalidades comunes (en pestañas y desplegadas)
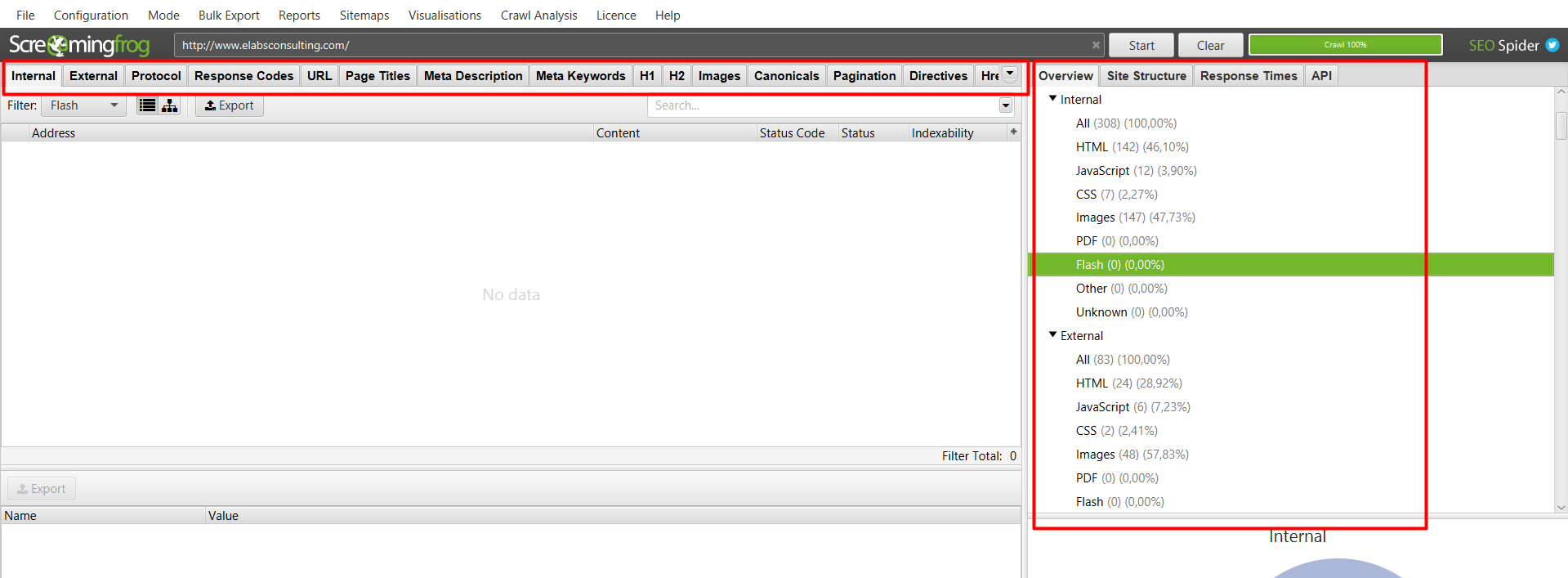
Estas dos secciones, son las mismas. Lo único que las diferencia es la cantidad de información visible a primera vista que nos ofrecen. Pues, tal y como vemos, en el menú superior nos ofrece la posibilidad de llegar a las secciones más específicas mediante pestañas como modo de atajo, y a la derecha en cambio, tenemos todas las secciones desplegadas con sus funcionalidades aparentemente visibles.
Sección 3: Campo de batalla
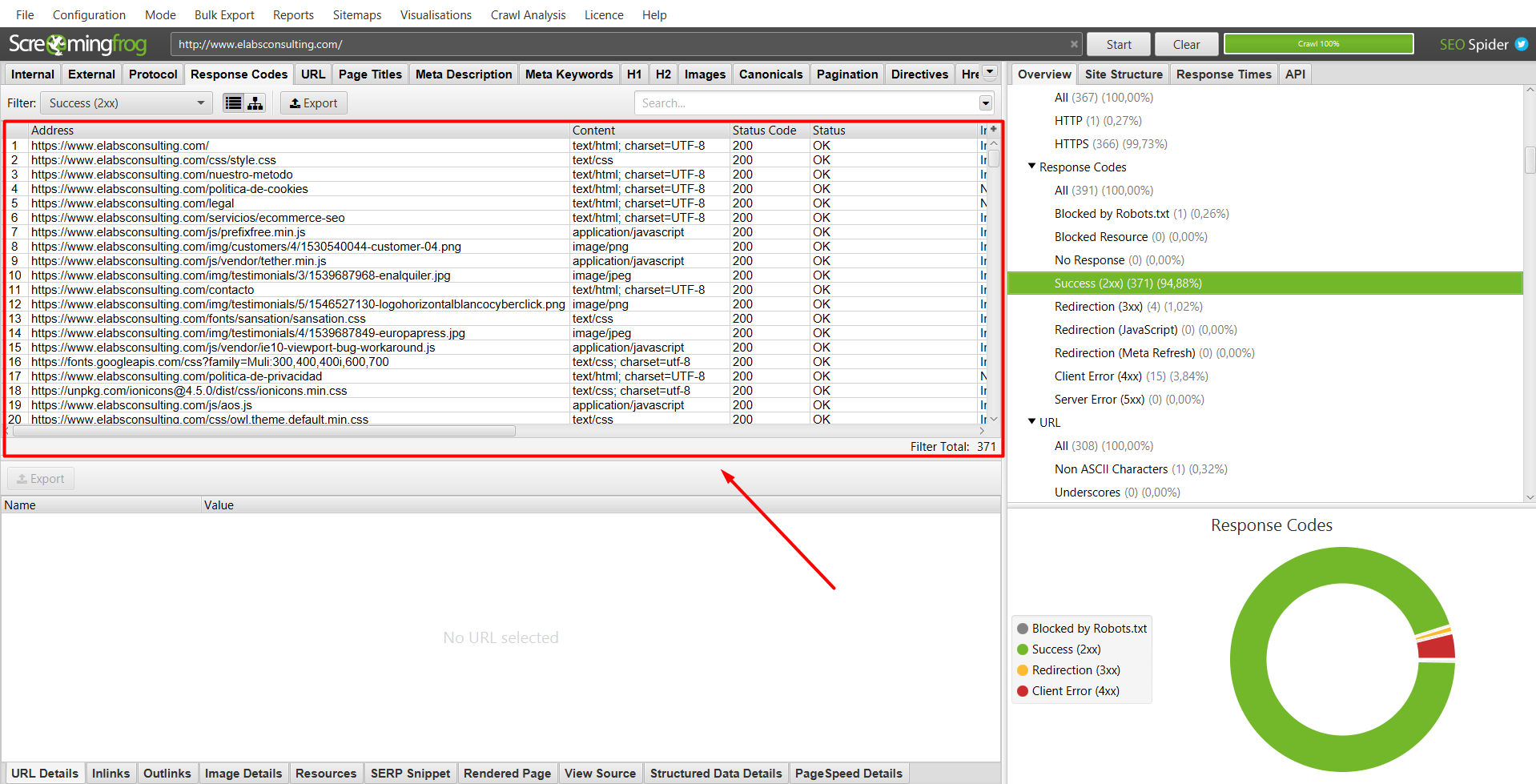
Esta sección es, sin duda, la más importante de todas. Pues es aquí donde vamos a ver de forma detallada, cada una de las urls y sus características principales (si se está indexando o no, en qué estado se encuentra, cuántos inlinks tiene, cuál es su tiempo de respuesta…).
Aún así, en el caso que queramos aundar aún más en el estado de la url y queramos verla en más detalle, tenemos la parte de abajo donde se nos detalla de forma más explícita todos los datos de la página seleccionada:
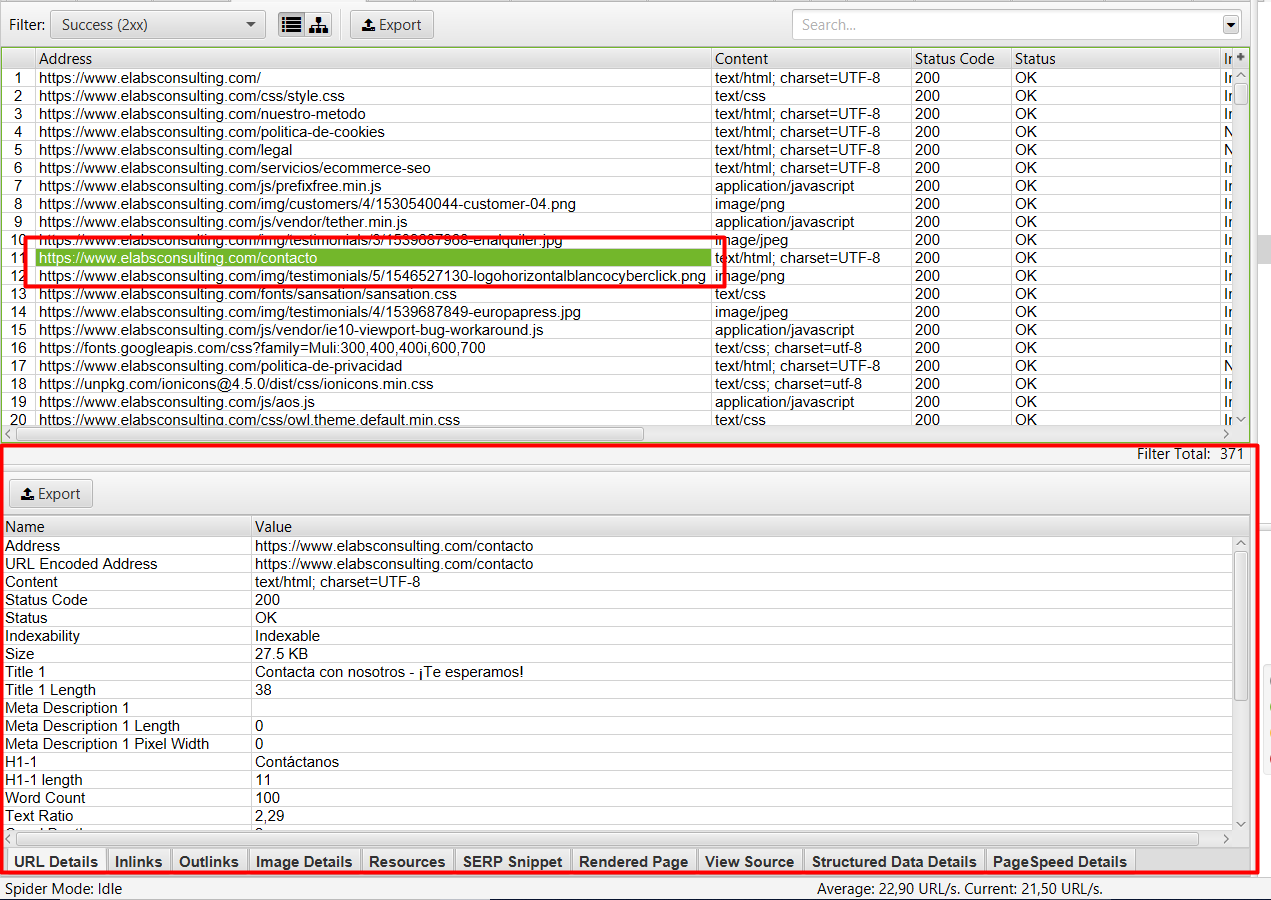
En esta sub-sección, vamos a ver no solo el número de inlinks tal y como nos mostraba en la categoría superior, sino que vamos a poder ver en detalle qué páginas internas están apuntando a la url seleccionada, a qué páginas está apuntando esta, detalles más específicos de la url como el título, meta description, H1, H2, y longitud de todos estos metatags…
Así que una vez vistas las 3 grandes secciones de las que está compuesta la herramienta de Screaming Frog, pasamos a ver cada una de ellas al detalle:
Checklist de apartados a analizar:
1. Mapa o Estructura web:
Esta funcionalidad, nos será súper útil para conocer una web que nos llega nueva, y que no sabemos cómo tiene distribuida su estructura. Así pues, mediante esta funcionalidad, podremos ver claramente las categorías y subcategorías, así como cuánto de cerca o lejos se encuentra una página del root domain.
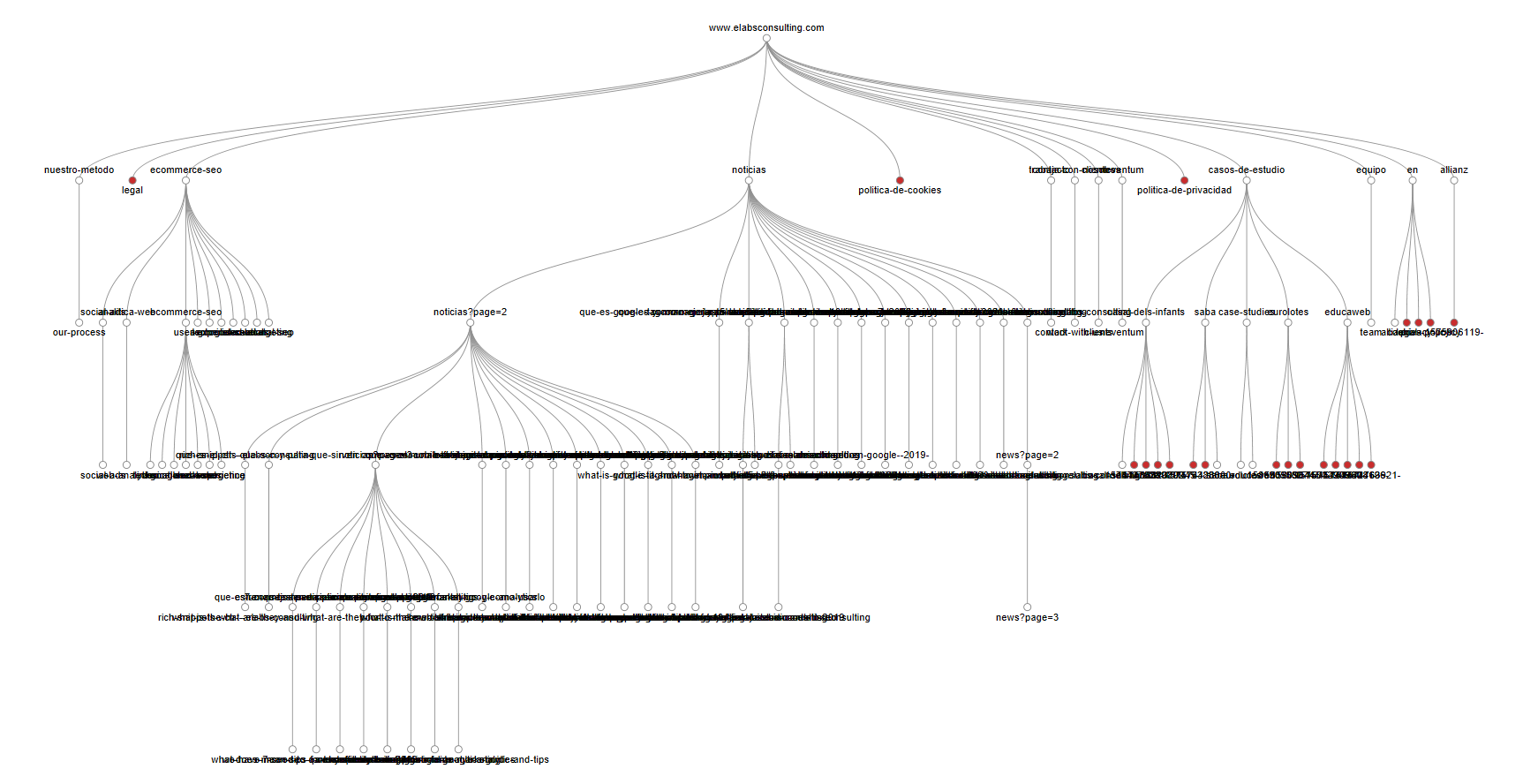
Para acceder a esta funcionalidad y poder ver el árbol web, tendremos dos opciones:
- Opción 1: Visualización > Crawl Tree Graph
- Opción 2: Visualización > Force-Directed Crawl Diagram
2. Estado y Salud de las URLs.
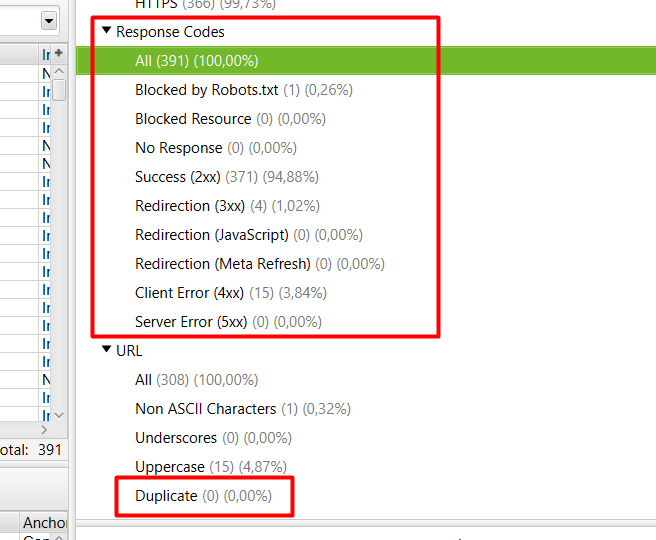
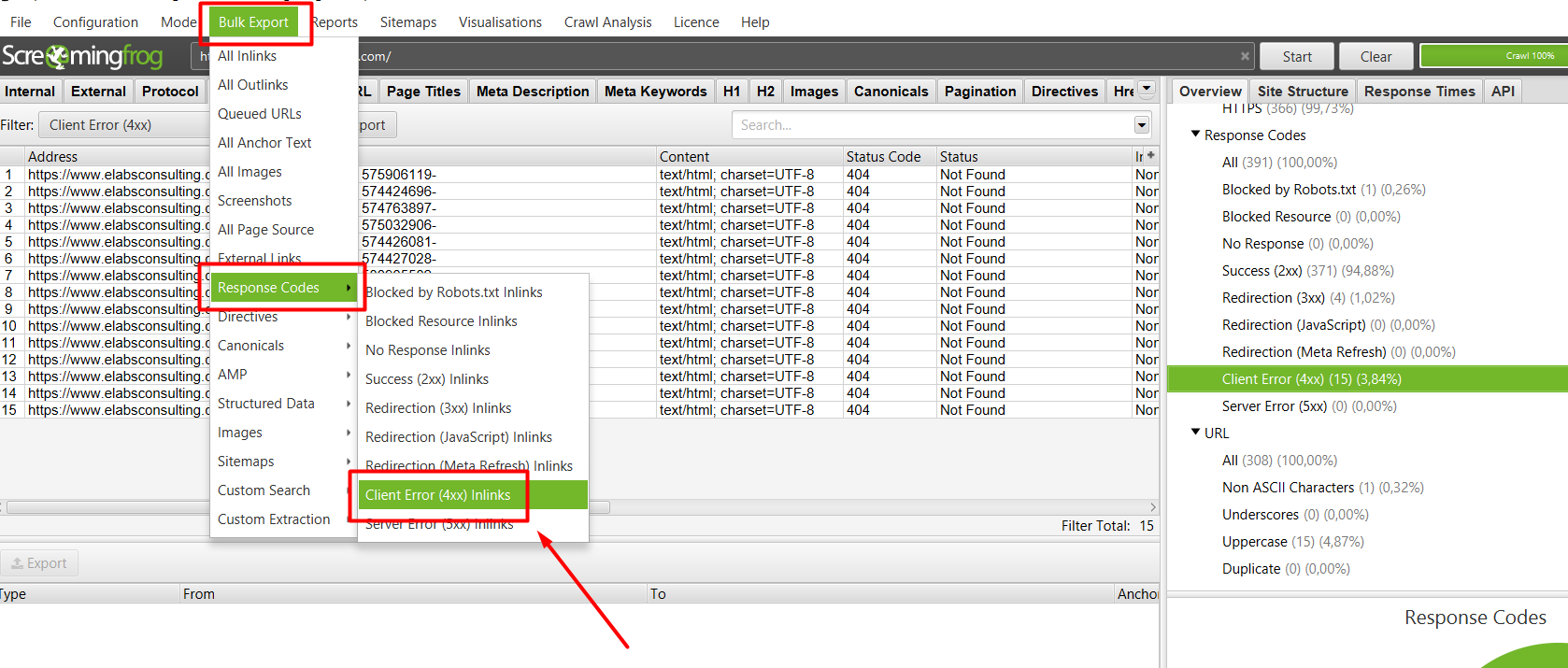
Estas funcionalidades forman parte de la sección 2 comentada anteriormente. En este apartado, nos será súper útil saber el estado de las urls de la web, y qué urls se encuentran afectadas. Para ello, deberemos ir a la pestaña de “Response Codes”, y seleccionar alguna de las subsecciones que nos proponen. Veremos que al hacer click en alguno de los códigos de urls, se nos aparecerán las páginas afectadas en el panel principal.
Las funcionalidades que nos ofrece esta sección, son las siguientes:
- Todas las URLs.
- Bloqueadas por robots.txt.
- Recursos bloqueados.
- Páginas que no responden (No response).
- Páginas que responden (2xx).
- Redirecciones 3xx.
- Redirecciones por Javascript.
- Redirecciones por Meta Refresh.
- Errores 4xx.
- Errores de servidor 5xx.
Observación: Asimismo, hay otra funcionalidad en la siguiente sección llamada “URL”, que nos será útil para complementar la información de la salud y estados de las URLs. En concreto, deberemos de fijarnos en las urls duplicadas.
3. Metatags
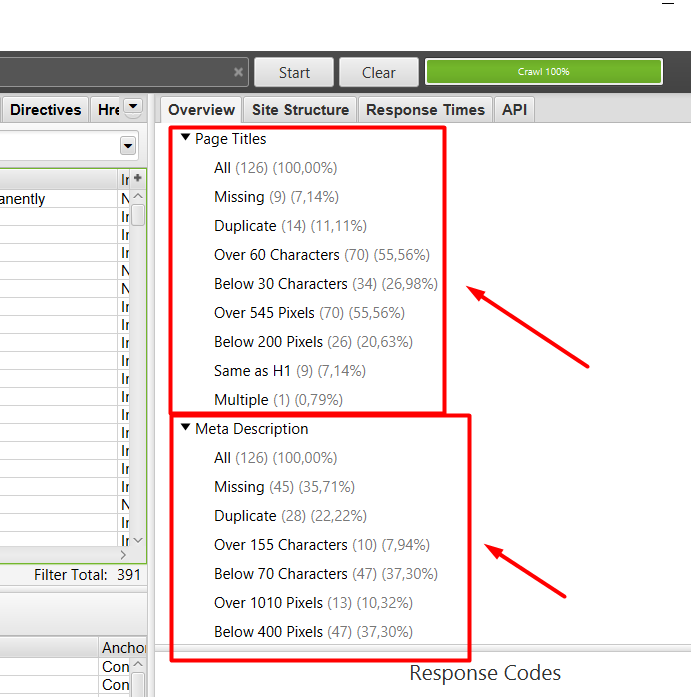
Las secciones que siguen, hacen referencia al estado en el que se encuentran los metatags del site. Para ello, las siguiente 4 secciones, serán importantes para ver cuan optimizados están estos metatags. Las secciones que deberemos tener en cuenta, son las siguientes.
- Title
- Metadescription
- H1
- H2
En cada uno de estos apartados, encontraremos información adicional, que nos advierten de las siguientes oportunidades:
- URLs que carecen del metatag.
- URLs con el metatag duplicado.
- URLs en las que los caracteres de los metatags sobre pasan lo recomendado.
- URLs con el metatag múltiple.
4. Imágenes.
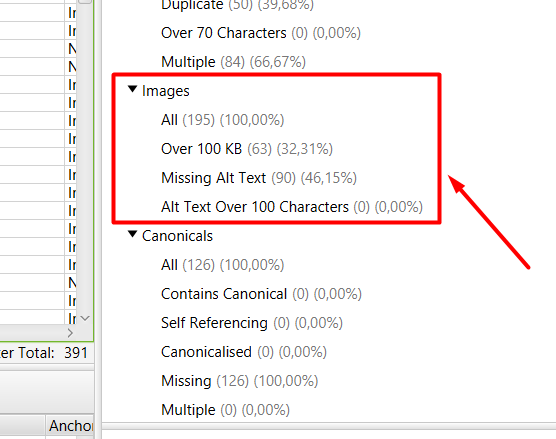
En este apartado, nos advierte de todas las posibles mejoras que tenemos en las imágenes de nuestra web. Para ello, Screaming Frog nos brinda la siguiente información:
- Total de URLs que tiene la web.
- Imágenes que sobrepasan el peso recomendado.
- Imágenes que carecen de optimización de texto ALT.
- Imágenes con texto ALT demasiado extenso.
5. Canonicals.
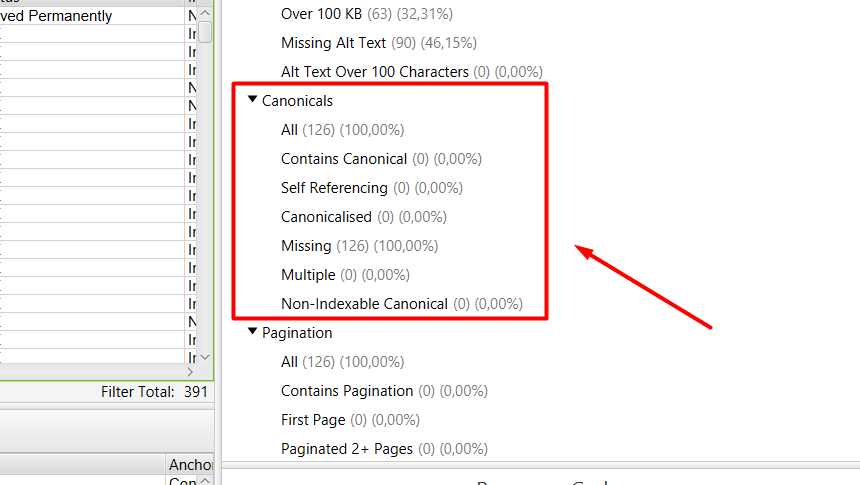
El siguiente apartado, hace referencia a las etiquetas canonicals de las que dispone la web. Para ello, la información que nos ofrece Screaming Frog, es la siguiente:
- Total de URLs del site.
- URLs que contienen la etiqueta canonical.
- URLs con etiqueta canonical que apunta a ella misma.
- URLs canonicalizadas.
- URLs que carecen de etiqueta canonical.
- URLs con etiquetas canonical múltiples.
- URLs con canonical no indexables.
Bien, una vez vistas las funcionalidades básicas que debemos conocer sí o sí al empezar a usar Screaming Frog, ahora vamos a ver las 2 funcionalidades extras que os hemos preparado, que os van a ayudar a sacar el máximo de información a vuestro análisis web:
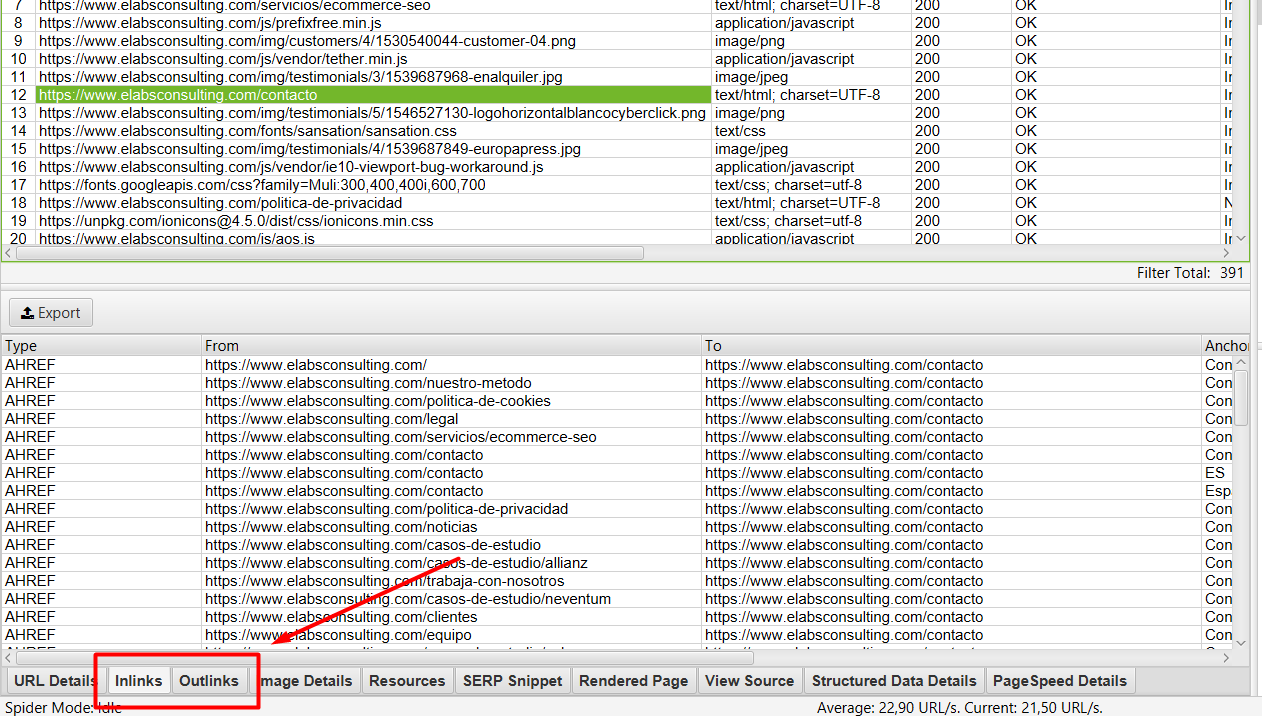
6. Inlinks y Outlinks.
Este apartado ya lo hemos mencionado en la sección 3. Y es que nos va a ser de gran ayuda, cuando tengamos que conocer a qué páginas internas están apuntando nuestras urls, y por qué páginas internas están siendo apuntadas. A todo esto, también vamos a poder saber mediante qué anchors text están siendo apuntadas, y si estos enlaces apuntan de forma directa o pasan por otra url antes.
Toda esta información, la encontraremos en las siguientes dos pestañas (aunque para que nos aparezca la información, deberemos primero haber hecho click en la url que nos interesa analizar):
7. Descargar los datos e interpretarlos.
Por último, deberemos saber cómo exportar toda esa información que vayamos recogiendo, pues al final se la tendremos que pasar al departamento de programación y/o contenidos para que lleven a cabo las mejoras y oportunidades que Screaming Frog nos propone.
Así pues, tenemos 2 formas de descargar los datos:
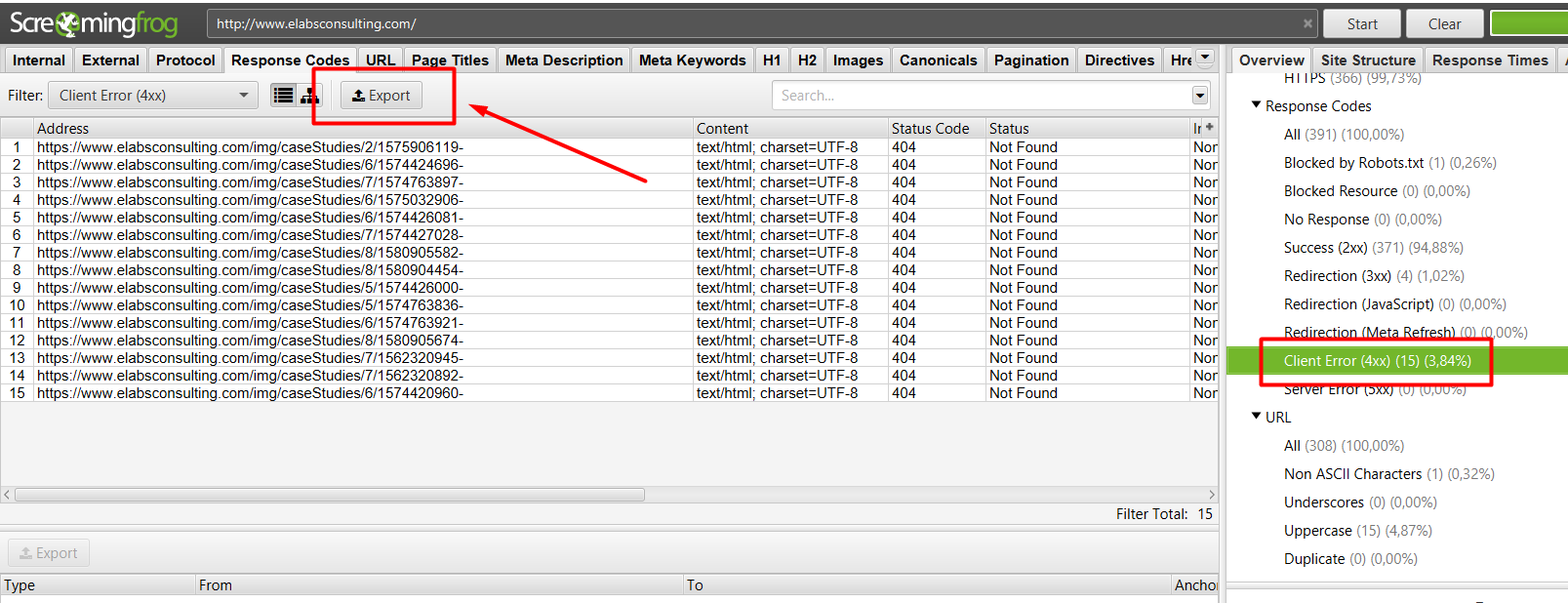
Alternativa 1:
Seleccionamos la información que queremos descargar (en este caso, nos interesa descargar todas las urls con errores 404), y hacemos click en el botón de “Exportar”:
Alternativa 2:
Con esta alternativa, no será necesario seleccionar la información o urls a descargar. Nos bastará con exportar los datos de forma paralela… ¡y voilà!